

Depuis que j’ai un site la photographie, je m’intéresse aux aspects cachés des sites internet sur la photographie, notamment le nombre de visiteurs. Pourquoi ? Parce que sur internet, vous avez ce que certains appellent la « cyber-réputation ». Cette notoriété numérique, constitue un facteur de différenciation et présente un avantage concurrentiel. Elle se façonne par la mise en place d’éléments positifs et la surveillance des éléments négatifs.
Par exemple, si un site internet sur la photo a 500 000 visiteurs uniques par mois et qu’un autre en a 30 000, lequel allez-vous visiter en premier ? Celui qui a en le plus ! C’est une façon de se créer une « cyber-réputation », et ce, même si elle est « fictive » et que le nombre de visiteurs uniques est inexact. De plus, la plupart des sites ne vous révèleront jamais ces chiffres, car pour eux c’est une source de revenu potentiel.
En effet, un site sur la photo qui a beaucoup de visiteurs, pourra exiger de la part des entreprises qui désirent afficher leurs publicités sur ce site, un certain montant d’argent. Je visite parfois le site Fstopper. Ce site sur la photo aurait, selon SimilarWeb, environ 6 millions de visiteurs par mois, ou 200 000 par jour. Il peut donc choisir les entreprises qui afficheront leurs publicités et exiger le montant qu’il veut, puisqu’il attire un très grand nombre de visiteurs. Mais ce chiffre est probablement faux. Voici pourquoi.
SimilarWeb et ses crawlers
Comment peut-on savoir le nombre de visiteurs d’un site sur la photo si ce site ne révèle pas ce nombre ? En estimant le nombre de visiteurs. SimilarWeb est un très bon exemple. Ce service en ligne gratuit est considéré comme étant l’un des meilleurs, avec un taux de précision allant de 10 à 20 %. Toutefois, pour parvenir à estimer le nombre de visiteurs, ils utilisent des « crawlers ». J’ai déjà posé la question à SimilarWeb, afin de savoir s’il utilisait réellement des robots. Voici leur réponse :

Donc SimilarWeb, utilise des crawlers. Mais le problème c’est que ces robots « indexeurs » seront perçus comme étant des visiteurs par les sites et s’ils ne sont filtrés, et qu’une entreprise veut savoir combien de visiteurs a un site Web, il utilisera les services de cet estimateur en ligne – ou d’un autre estimateur. Mais ces données seront fausses, car il y a de plus en plus de robots qui ratissent le Web que d’humains qui visitent les sites internet.
Plus de robots que d’humains
Le problème avec la plupart des sites internet sur la photographie, c’est qu’ils ne tiennent pas compte si ces visiteurs sont des humains ou des robots (des crawlers en anglais). En effet, le nombre de robots qui ratissent le Web est énorme. Selon les chiffres d’Incapsula, qui est un CDN (content delivery network), ou réseau de diffusion de contenu, 51.8 % des visiteurs d’un site internet sont des robots et 48.2 % sont des humains. Voici un graphique montrant le pourcentage de robots en 2016 selon Incapsula :
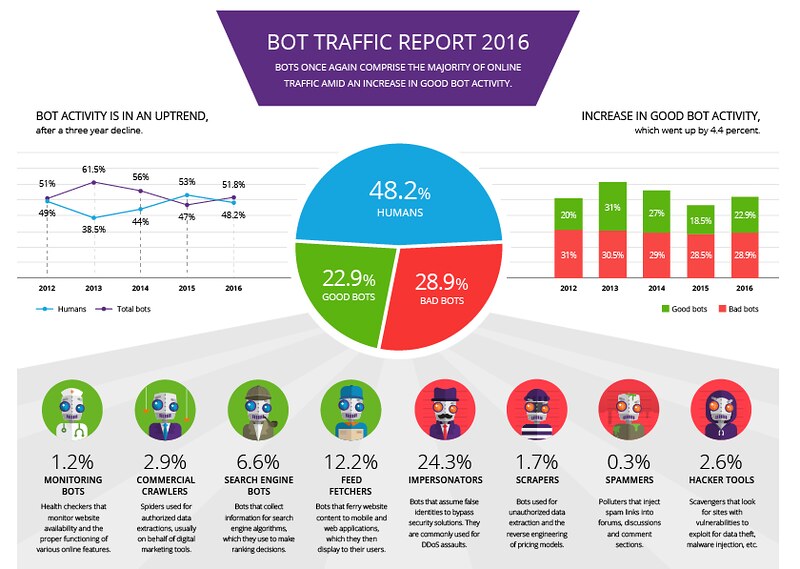
Un faux trafic
Tous ces robots génèrent un trafic vers les sites internet, lesquels sont comptés comme étant des visiteurs. Cette technique est en réalité une « fraude », car s’il y a plus de robots que d’humains, le nombre de visiteurs d’un site internet est donc inexact. Incapsula, offre une protection en filtrant les robots et en ne faisant passer que les humains. Bien sûr, il existe des trucs pour contourner la sécurité offerte par un CDN comme Incapsula, mais très peu de gens savent comment procéder, car il faut être très bon en programmation informatique.
Et pour compliquer les choses, vous avez de « bons » robots et de « mauvais » robots. Mais au final, le résultat est le même : ils génèrent un faux trafic. De plus, les sites internet seront ralentis en raison d’un plus grand trafic généré par une quantité croissante de robots. Le comportement d’un robot d’indexation résulte de la combinaison de ces 4 principes :
- Un principe de sélection qui définit quelles pages télécharger.
- Un principe de re-visite qui définit quand vérifier s’il y a des changements dans les pages.
- Un principe de politesse qui définit comment éviter les surcharges de pages Web (délais en général).
- Un principe de parallélisation qui définit comment coordonner les robots d’indexation.
Toutefois, très peu de robots respectent ces principes et il n’est pas rare de voir 50% des visites provenant de Googlebot.
Est-ce possible de s’en débarrasser ?
L’unique façon de se débarrasser de ces robots ne se fait pas via le fichier « robots.txt« , qui est un fichier texte utilisé pour le référencement naturel des sites web, contenant des commandes à destination des robots d’indexation, car la plupart des robots ne respectent pas les commandes se trouvant dans ce fichier. J’ai déjà testé ce fichier en incluant des commandes pour exclure certaines parties de mon site, et le robot de Google n’a pas respecté ces commandes. Il a continué à « crawler » des parties de mon site.
Voici une preuve que les robots explorateurs peuvent nuire et ne respectent pas le fichier robot.txt. Sur le forum de StatCounter un des membres nous explique son problème :
Il y a quelque chose de très étrange qui se passe sur mon site, et j’espère que quelqu’un pourra m’aider. J’utilise à la fois StatCounter et Google Analytics pour surveiller mon trafic. Une chose que j’ai remarquée sur StatCounter est que j’ai une très grande quantité de trafic venant d’Amazon.com (Ashburn, Virginia) qui semble être le trafic des crawlers. Au cours des dernières semaines, j’ai vu plus de 40 % de mon trafic provenant des robots d’exploration, et aujourd’hui, en particulier, il est de 73 %. Que pourrait-il se passer ?
En outre, et je me pense que c’est lié, j’utilise Adsense et j’ai vu un grand nombre de clics non valides qui stimulent mon CTR, mais n’étaient pas enregistrés pour avoir du revenu. La chose étrange est qu’Adsense et Analytics enregistrent les clics, mais StatCounter ne montre pas l’activité de lien de sortie sur les annonces Google pour refléter ce qui est rapporté dans Adsense. Est-ce que cette étrange anomalie de clics sur les annonces peut être liée au trafic du robot d’indexation Web signalé par StatCounter ? Et que devrait-on faire au sujet de cette situation de trafic Web car c’est très étrange que le robot d’exploration d’Amazon puisse causer de tels problèmes. Voici ce que j’ai ajouté à mon fichier .htaccess :
Order Deny, Allow
deny from www.amazonaws.comBien sûr, cela ne peut pas bloquer tout le trafic du robot d’exploration d’Amazon, mais il bloquera la majorité du trafic. Si vous rencontrez ce problème et que vous voulez trouver les autres réseaux à bloquer, je vous suggère de rechercher les plages IP. Il y en a pas mal. »
Après qu’un membre du forum lui ait dit que les robots ne cliquent pas sur les annonces, il a répondu :
Je suis d’accord que les robots ne cliquent pas sur les annonces. Toutefois, en bloquant le trafic des robots, cela a permis d’arrêter les clics non valides sur les annonces. Lorsque j’autorise à nouveau ce trafic, les clics sur les annonces redémarrent immédiatement. Malheureusement, je ne peux pas suivre les adresses IP exactes des robots d’exploration qui sont les coupables, car seul Google Analytics affiche les clics, mais il ne montre pas les adresses IP dans le cadre de leurs objectifs de sécurité. Cependant, je peux voir les réseaux qui ont généré les clics d’annonce non valides et ils proviennent tous d’amazonaws, puis, revenant à StatCounter, je peux voir que tout le trafic d’amazonaws a été le trafic généré par un robot.
Donc, dans ce cas, pour une raison quelconque, les robots d’exploration cliquent sur des publicités. Pire, les annonces hébergées dans un répertoire ne sont pas autorisées dans le fichier robots.txt.
Des virus déguisés en crawlers
Amazonaws est en fait un virus qui est propagé par les visiteurs via leurs navigateurs directement depuis leurs ordinateurs. Ce virus, lorsqu’il se propage sur un site internet, peut générer un faux trafic et cliquer sur des publicités. De plus, il n’apparaît jamais directement comme amazonaws, mais plutôt avec un préfixe comme S3.amazonaws.com. Le Webmaster du forum StatCounter, a simplement omis de spécifier entièrement le nom de ce virus / robot.
Comme vous pouvez le constater, les crawlers, peuvent être une source de problèmes car certains pirates les utilisent pour attaquer un site, pourtant SimilarWeb – et plusieurs autres services en ligne – les utilisent. Mais ils savent que ces robots peuvent être une source de problèmes, mais tout ce qui compte pour eux est de vous montrer une estimation du trafic d’un site, qui bien souvent est incomplet, pour que vous passiez au plan professionnel, lequel coûte environ 200 $ par mois.
D’ailleurs j’en ai fait les frais à mes débuts avec mon blog. J’étais continuellement attaqué par un botnet. Mon site pouvait planter plusieurs fois par jour. Ce qui m’a sauvé c’est Incapsula. Cette entreprise américaine offre une protection contre les botnets en départageant les robots des humains, et si un visiteur arrive sur mon site et que son ordinateur est infecté, il sera également bloqué.
Utiliser un CDN pour se débarrasser des crawlers
En fait, il est très difficile de se débarrasser de ces crawlers, parce qu’il y en a des dizaines (entre 50 et 70), mais aussi parce qu’ils ne respectent pas les commandes des fichiers robots.txt et .htaccess, lequel permet de définir des règles destinées aux serveurs Apaches. Ces crawlers peuvent également changer d’adresse IP.
Et puisque la plupart des sites qui estiment le nombre de visiteurs utilisent des crawlers, vous ne pouvez pas vous fier à ces sites, car si vous utilisez un CDN qui permet de bloquer tous les crawlers, sauf ceux que vous avez choisis, notamment Googlebot, ces sites estimateurs vous fourniront des chiffres qui seront inexacts.
Selon mes recherches, Incapsula est le seul CDN qui offre cette fonctionnalité, tous les autres ne font qu’accélérer ou protéger un site en ayant des serveurs répartis dans plusieurs pays. Voici un exemple (vous pouvez cliquer sur l’image pour l’agrandir) :

J’ai mené ma petite enquête, en questionnant plusieurs CDN, dont Cloudflare, MaxCDN, Limelight Networks, keyCDN et quelques autres. Ils m’ont tous répondu qu’ils protégeaient et accéléraient les sites internet. Lorsque je leur ai posé la question, s’ils filtraient et éliminaient les robots indexeurs (les crawlers), ils m’ont tous dit qu’ils n’offraient pas cette fonctionnalité.
Un exemple
Cela veut donc dire que lorsqu’un site sur la photo affirment avoir par exemple 500 000 visiteurs uniques par mois, vous devez prendre ce chiffre, le diviser par 30 – pour le nombre de jours qu’il y a dans un mois, puis diviser le résultat par 2 , qui en arrondissant, représente le 52 % de crawlers qui circulent et génère un faux trafic pour tous les sites sur internet (lorsque les robots ne sont pas filtrés et bloqués).
Nous obtenons le nombre beaucoup moins impressionnant de 8 333 visiteurs uniques par jour. Si les sites sur la photo ne bloquent pas les crawlers, ce nombre s’élèverait à 16 666 visiteurs uniques. De plus certains robots peuvent crawler un site plusieurs fois en 24 heures, cela signifie qu’un site peut avoir encore moins de véritables visiteurs par jour.
Prenons un exemple concret. Je visite parfois, le blog DIYPhotography.net. Selon SimilarWeb – qui utilise des crawlers pour récolter ses données et faire ses estimations – ce site aurait eu 784 312 visiteurs pour le mois de septembre 2017. En divisant ce nombre par 30, nous obtenons 26 143 visiteurs par jour. En divisant ce résultat par 2 (les fameux 52 % de crawlers qui génèrent du faux trafic), nous obtenons 13 071 visiteurs par jour. De plus il faut tenir compte du Bounce Rate, qui est un indicateur marketing qui mesure le pourcentage d’internautes qui sont entrés sur une page Web et qui ont quitté le site après, sans consulter d’autres pages. Ils n’ont donc vu qu’une seule page du site. Pour le site DIYPhotography.net, le Bounce Rate est de 83.79 %.
Cela signifie que 83.79 % des visiteurs ont quitté après consulter une page. Donc si ce site sur la photo a réellement reçu environ 13 071 visiteurs uniques par jour, 10 952 visiteurs ont quitté après avoir consulté un article. Il ne reste plus que 2 119 personnes qui se sont vraiment intéressées à ce site sur la photo. Nous sommes très loin d’un site « populaire ». À moins bien sûr que les données de SimilarWeb soient fausses.
Mon site et Incapsula
Mon site est protégé des attaques des pirates informatiques par Incapsula, mais en plus cette entreprise filtre et bloque tous les crawlers, sauf ceux que j’ai choisis, notamment Googlebot, qui est vitale pour qu’un site internet puisse exister, car Google est utilisé par 77.43 % des internautes dans le monde :
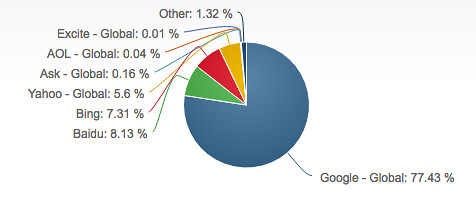
Cela signifie que le nombre de visiteurs qui consultent mon site est réelle et qu’il n’est pas faussé par les 52 % de crawlers qui génèrent du faux trafic sur le Web. Cela signifie également que des estimateurs en ligne comme SimilarWeb, ne peuvent pas afficher le nombre réel de visiteurs que je reçois par mois, puisqu’ils utilisent tous des robots indexeurs pour faire leurs estimations et que je les bloque.
SimilarWeb n’est pas précis
Mais ce qu’il y a de plus grave, outre le fait que tous ces crawlers génèrent du faux trafic, c’est que SimilarWeb, qui affirme être le meilleur estimateur sur internet, présente des données qui ne reflètent aucunement la réalité. Selon le site internet Tnooz, qui est un média indépendant couvrant la technologie, la distribution numérique, les médias, le marketing, les startups et le financement dans le secteur du voyage, au début d’avril 2015, ce site estimateur a révisé son algorithme. À partir de ce moment, les estimations du nombre de visiteurs sur le Web ont diminué de moitié pour de nombreux sites internet de voyages.
Les annonceurs et les investisseurs qui s’appuient sur ces données pour obtenir une analyse concurrentielle, peuvent être déçus par les performances de plusieurs sites. Par exemple, selon SimilarWeb, le portail de voyage de Yahoo aux États-Unis aurait diminué de 52% pour ce qui est des visiteurs mensuels. En mars 2015, il comptait 4.9 millions de visiteurs; en avril de la même année : 2.8 millions.
Cette prétendue diminution est illusoire, car comment un site internet comme Yahoo Travel (US), peut-il avoir eu jusqu’à 52% moins de visiteurs en un seul mois ! Il s’est produit la même chose pour de nombreux sites internet de voyage aux États-Unis et dans plusieurs autres pays. Voici les estimations de SimilarWeb du nombre de visites mensuelles de plusieurs sites entre mars et avril 2015 :
- Condé Nast Traveler (US) et TravelandLeisure (US) une diminution de 54%.
- National Geographic Traveler (US) une diminution de 44%.
- Afar une diminution de 206%.
- Fodors.com et Frommers.com une diminution de 50%.
- Rough Guides une diminution de 50%%. Rick Steves aussi une diminution de 50%.
- Lonely Planet une diminution de 23%.
- Matador Network une diminution de 64%.
- BootsnAll une diminution de 44%.
Donc SimilarWeb, modifie son algorithme comme bon lui semble, sans tenir compte des répercussions que cela peut avoir pour les sites internet.
Qui utilise SimilarWeb et son algorithme ?
Les annonceurs, les sociétés de marketing, les réseaux publicitaires et plusieurs entreprises, adhèrent à des services d’analyse pour obtenir des informations détaillées sur les stratégies marketing, le trafic via les mobiles et le trafic des sites internet venant des ordinateurs de bureau. Donc, la révision de l’algorithme a touché de façon disproportionnée plusieurs sites Web.
En résumé, non seulement plusieurs sites estimateurs présentent des chiffres totalement erronés, mais cela a une répercussion sur le nombre de visiteurs des sites sur la photographie. Les robots d’indexation générant du faux trafic, les sites sur la photo « mentent plus ou moins volontairement », sur le nombre de visiteurs pour que des annonceurs soient intéressées à afficher leur publicités sur leurs sites.
Conclusion
Au final, tout cela met en péril la « cyber-réputation » des sites internet puisqu’ils doivent mentir et que les annonceurs et visiteurs peuvent consulter des sites comme SimilarWeb, qui sont en fait totalement imprécis, et ce, contrairement à ce qu’ils affirment. Après avoir lu cet article, si tout cela ne vous choque pas, moi oui, car ce que font tous ces sites estimateurs avec leurs crawlers qui génèrent du faux trafic, est de la pure supercherie qui peut avoir un impact très important pour tous les sites sur la photographie.










6 réponses
Surprenant de voir ces impacts des Robots, je croyais pourtant que c’était négligeable. Comme quoi…
En effet, il y a plus de robots que d’humains et ils produisent du faux trafic. Cela est impardonnable, car ils nuisent à tous ces sites. J’aurais pu donner plusieurs autres exemples. Mais mon article aurait été trop long à lire.
Je te remercie pour cet important article.
Merci, je croyais qu’il était important de souligner ces faits, car tout cela peut avoir un impact important pour plusieurs sites en photographie. SimilarWeb et les autres « estimateurs » peuvent nuire, mais ils ne regardent que le profit qu’ils peuvent faire, sans se soucier des répercussions que cela peut avoir pour tous ces sites.
Il en va de même pour des sites style 500px où j’ai l’impression qu’il existe de nombreux faux compte
Bonjour,
merci beaucoup pour cet article très intéressant et passionnant.
Sur mon site, j’ai aucune publicité. Il me sert uniquement à mettre en ligne nos prestations que ce soit pour la photographie d’art ou les stages photos.
Notre premier critère d’évaluation est le nombre de nouveaux contacts que nous générons chaque jour : entre 2 et 3.
Le plus important pour nous est le taux de conversion qui va suivre.
Nous n’attachons pas une grande importance aux statistiques visiteurs. Ce qui nous intéresse c’est le nombre de pages vues pendant une visite mais surtout le taux de bouncing et le temps passé sur le site.
Le nombre de visites n’est pas important pour nous. Le plus important c’est combien d’internautes s’inscrivent quotidiennement à notre newsletter ou combien nous demande des informations pratiques. En dessous de 3 demandes par jour, ce n’est pas une bonne journée.
Cela peut paraitre étrange de ne pas se soucier en premier des visites mais à quoi sert d’avoir des visites si on ne génère pas de chiffre d’affaire?
Merci encore pour ce blog si intéressant
Bien à vous
Amar Guillen